Abstract
Speech-driven 3D facial animation research has shown promising results, but most methods rely on representations that are not compatible with production pipelines. In this work, we present a deployable system that bridges this gap by enabling speech-driven 3D facial animation directly in Unreal Engine (UE) using ARKit-compatible representations. We construct the 3DMEAD-ARKit dataset by converting the MEAD corpus into blendshape sequences using MediaPipe, and retrain FaceDiffuser and ProbTalk3D-X to generate stochastic and emotion-controllable animations. We further develop a modular UE plugin with a Python backend that supports model selection and parameter control. We compare our results to two existing commercial tools: Epic Games’ MetaHuman speech-driven animator and NVIDIA Audio2Face with a perceptual user study. The results highlight the importance of comparisons among academic and commercial pipelines. We recommend watching the supplementary video. We also plan to do live demonstrations at the conference.
Video
The supplementary video contains a teaser and a practical demonstration of the AutoFaceARKit plugin for Unreal Engine 5 generating facial animations using speech-driven facial animation models.
Dataset Processing Pipeline

Step 1: Original MEAD video frame
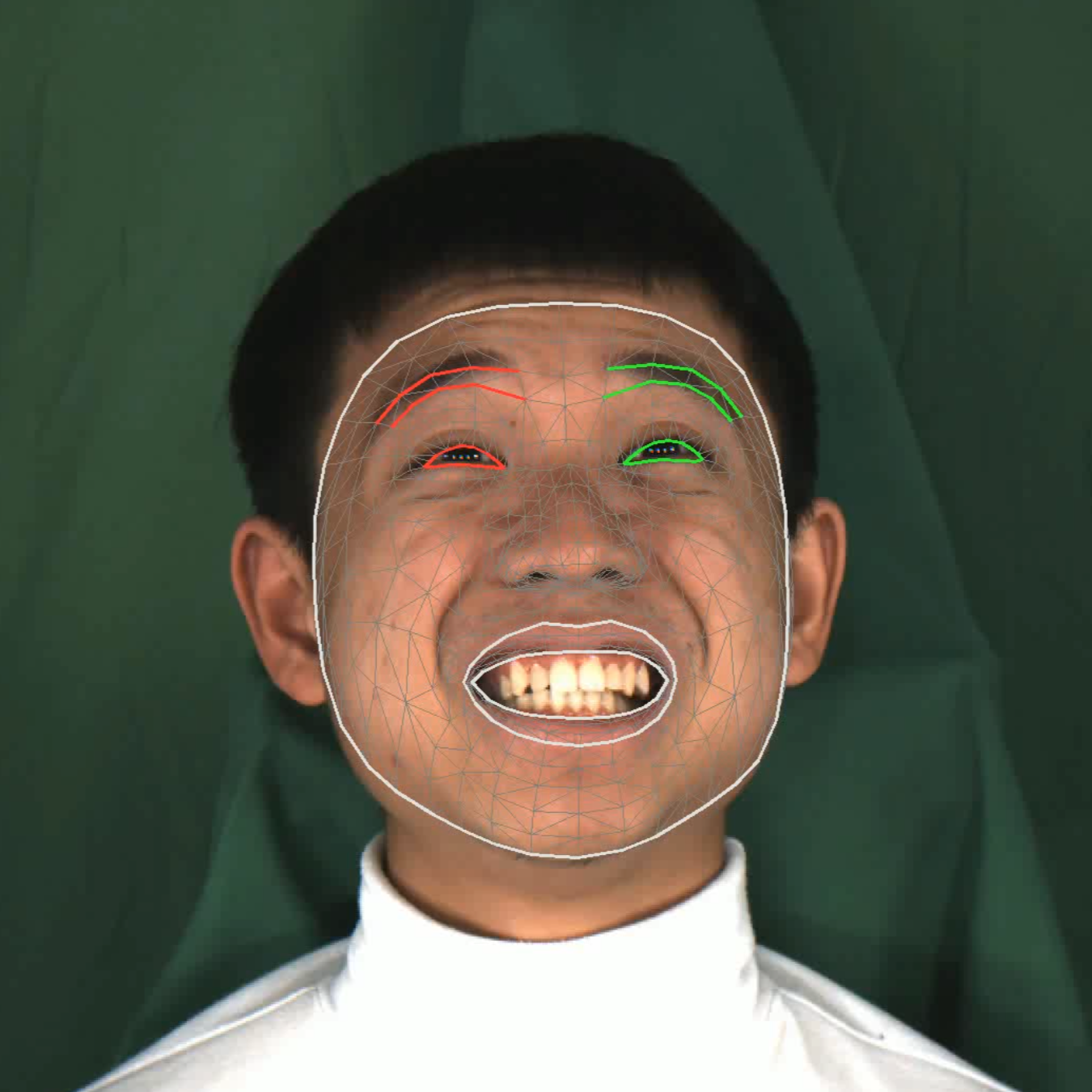
Step 2: MediaPipe facial landmark tracking

Step 3: Resulting ARKit ground-truth animation
Figure: Dataset processing pipeline. From left to right: Original MEAD video frame, MediaPipe facial landmark tracking, and the resulting ground-truth animation rendered onto an ARKit-compatible digital human.
System Architecture Overview
Figure: System overview. (1) In the frontend interface, the user can select the model, input audio (existing or live recording), conditioning style (i.e., speaking style, emotion, intensity), and a digital human character. (2) The data is passed to the backend process for generating the animation data. (3) After the inference, the data is sent to the engine which is used to create, apply to the selected character, and save the animations in the animation library, allowing the user to also retarget the saved animations to other compatible characters.
Perceptual User Study Evaluation
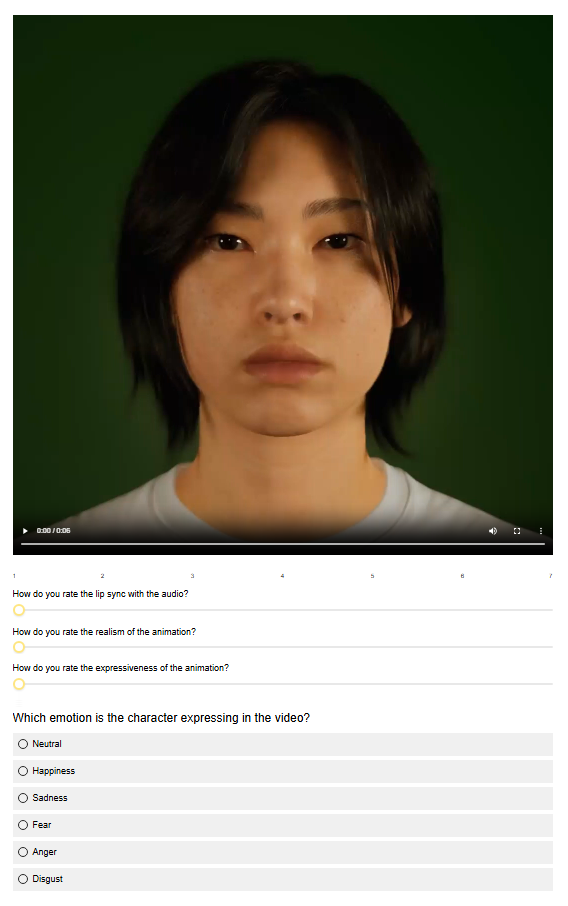
Figure: Questionnaire layout. Interface and survey layout presented to participants during the evaluation. This template displays the full setup used for Experiment 1, which included the emotion recognition task. For Experiment 2, the setup was identical but the final emotion classification question was omitted.